BeatrustのEngineering ManagerをしているRyo(長岡 諒)です。
みなさま年末はどのようにお過ごしでしょうか?
春にこのBeatrust Tech Blogを立ち上げたのですがわたしはまだ1記事も書いたことがなかったので、12月の頭に「年内に1記事も書いてなかったら過去に1回以上書いたことある方に焼き肉おごる」と宣言して締め切りに追われていました。
みんなに焼き肉をごちそうする機会は持ち越しになってしまいましたが、Beatrustの変化や創業初期のプロダクトにおいてスピードと品質のバランスをとりつつ進めるにあたりどのようなプロセス・環境を整備してきたかをまとめました。プロダクト開発されている皆さんのご参考になりましたら幸いです。
品質への取り組みとしては2021年でリリース&障害対応プロセスの整備と大規模ユーザー検証環境に注力してきました。本記事では背景から記述していますが、どういった取り組みをしたかを知りたい方は”具体的なKAIZEN内容”から確認いただくことができます。
2021年の振り返り
Beatrustはプロダクトを2020年の夏にリリースしたばかりのスタートアップなのですが、2021年は様々なFeatureをリリースしてきました。
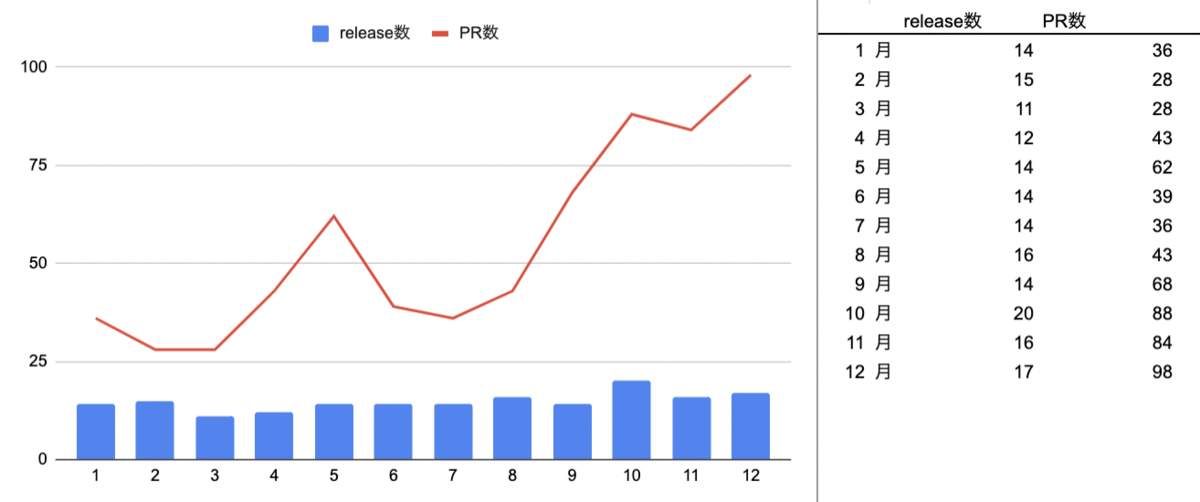
2020年末と比較してフルタイムのエンジニア社員はわたしも含めて3名→6名となり、業務委託でフルタイムの方が現在1名とパートタイムで1~2日/週の方が1名おり、この1年で653個のPRをclose/mergeし、177回のリリースを行ってきました。リリースはそのタイミングでリリース可能なPRをまとめて検証環境で最終確認してからリリースしており、9月と11月にフルタイムの社員が増えPR数が増えてますが、リリースを意図的に減らしていた3~4月以外はビジネスの成長に合わせて大小様々なFeatureやKaizenを週に3.5~5.0回程度のリリース行ってきました。
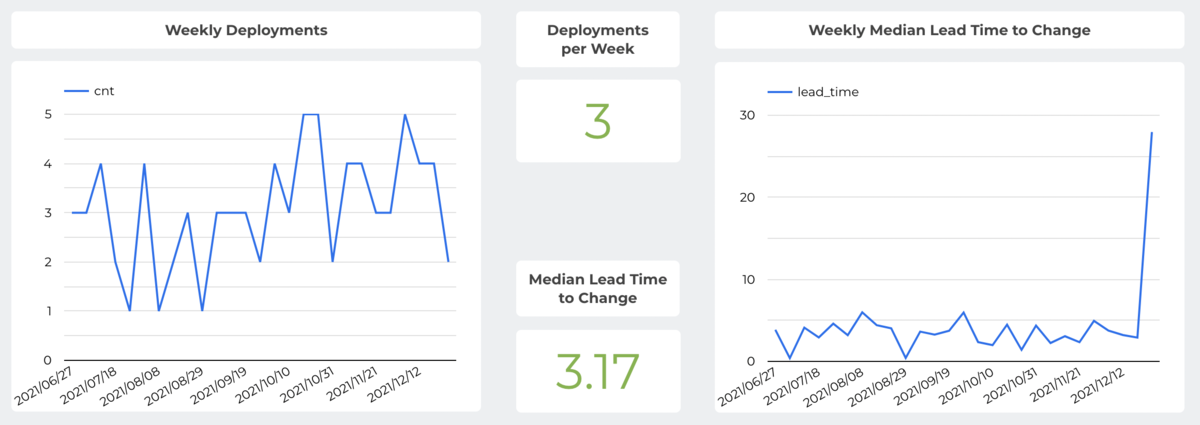
この図はSREのYutaがFour Keysを参考にDevOpsのメトリクスを可視化してくれたものですが(bi-weeklyのふり返りの際に参照しています)、ビジネスの成長に合わせて増えるユーザ数に応えるだけではなく、品質向上を行いながら開発スピードを安定させる取り組みを行ってきました。2021年12月現在ではPRリリースまでのlead timeは3.17回/日(中央値)となっており、最後に右側のグラフが跳ねているのはmonorepoにおけるyarn berry対応という一ヶ月かかった大きなPRがまさに今週リリースされたからです。
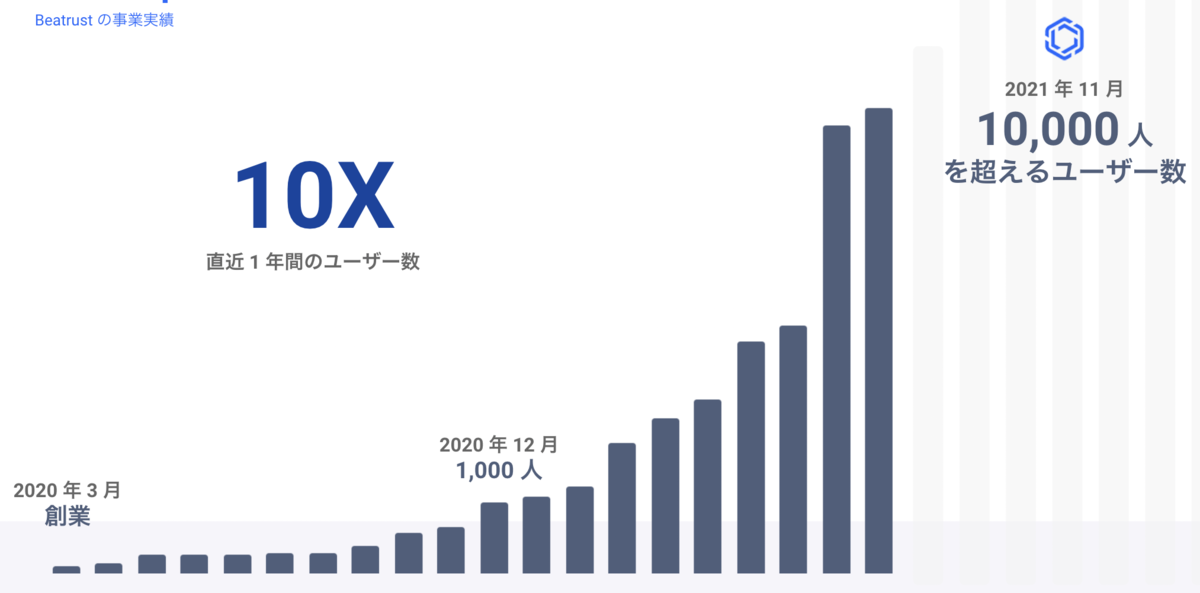
また、こちらの図は 会社説明資料 で公開しているものですが、去年の12月時点で1,000名台だったユーザー数は今年11月時点で10倍にあたる10,000名を突破しました。エンタープライズ向けのBtoBのSaaSを提供しているのですがEnterpriseにおいては1社増える際に過去最大規模の数倍のユーザーが利用し始めることもあり、良い意味でドキドキするユーザー数にもなってきました。
一方、同時に2021年はユーザー数増や期待に応えつつ、過去の負債と戦う日々でもありました。2021年始めには、いくつか問題が発生したこともあり、年間を通してプロダクトリリースプロセスのKAIZENが重要になってきました。
どういったKAIENに取り組んだかは本記事で記載していきますが、当時はライブラリVersion UPのリリース後に特定のブラウザで閲覧できなくなったり、ユーザー数増に比例して増えたメール配信時に問題が発生したり、かつそれらが重ねて発生した時期もありそのタイミングは精神的にも体力的にもしんどかったです。
年間を通して十数回そういった問題を発生させてしまいましたが、2021年期初から比較すると色々整備をしたこととにより障害発生から関係者への連絡が早く、収束も数時間以内で行えるなど、リリーススピードを損なうことなく品質向上の取り組みができてきたかと考えています。そういった、創業初期のスピードと品質のバランスをとりつつ進めるにあたってどういった形を構築してきたかの参考になればと思い本記事にまとめております。
KAIZENを行う障害の定義
KAIZENを行う根本には、様々な問題や障害があります。”障害”の言葉の定義は理由や文脈によって様々だと感じており、インシデント、イシュー、バグ・・・などあります。そこで2021年初期の障害多発時期に社内で"インシデント"の元になる障害の認識をあわせることから始めました。整備した定義は以下の通りです。
Beatrustにおける障害の定義
特定の主要な機能を利用できない状態が継続的に続いている状態。ないしは間違った対象に間違った情報が届くなどのセキュリティインシデントにつながる問題の発生。
これらは、我々が認証を受けているISMSの情報セキュリティインシデント(p.18) や ITILの インシデント(ITmediaの記載) の定義も参考にして整備しました。障害と判断した際には迅速な対応を行うためにSlackのchannelを作成したり、収束後に振り返りを実施するなど再発防止含めて「ちゃんとKAIZENする」プロセスを整備してきました。
例えば次のような例です。
※これらは全て起こったものではなく共通認識を得るために必要な分類表とお考え下さい。
| ケース | 種別 | 備考 |
|---|---|---|
| 定期配信の通知メールが配信できず短時間での再送も困難 | 障害 | OOMが発生していて再送しきれなかった場合もここに該当 |
| 想定外の挙動で意図しない同一組織の方に対してメール・通知が配信される | 障害 | |
| 配信したメールのURL含めて、主要な導線が正常に利用できない | 障害 | |
| サポート対象の任意のブラウザで常にエラーが発生して主要な機能が仕様できない | 障害 | |
| 特定の組織・ユーザーの環境に依存して特定の操作ができない | 個別判断 | 悩ましい場合がありますがネットワーク環境などの場合がある |
| 連打など画面にエラーが表示されするが再度実行すると正常に動作する | バグ | 主要な導線で毎回1回目がエラーになる場合は障害 |
| システム管理者用の運用画面でエラーが発生して特定の機能が利用できない | バグ | ごめんなさいですがバグ・エラー |
| 本来閲覧する権限のない方に個人情報が閲覧された | セキュリティインシデント | 過去発生してないですが発生したら緊急事態 |
いくつか例を挙げるとこのような基準になっています。(”主要なXX”は厳密に定義しきれているわけではないですが、ユーザーが利用を開始してほぼ確実に利用する機能が該当し、影響度合いに応じて障害かを判断しています)
プロダクトの特徴
Beatrustは、一部で特定のコミュニティー向けにも提供してはいますが、2021年末時点ではLarge Enterpriseのお客さまが大半を占めており以下のユーザー/プロダクト特性があります。
- 導入企業ごとに開始や行動特性が異なり、お客さま社内でのアナウンスにより急にアクセスが増えるなどがある
- メールで連絡する文化のお客さまも多いことから、Beatrustのメルマガの影響は大きくとても重要な施策となっている
- データベースのマルチテナント方式を採用しており、各テナント(組織)の情報は他のテナントから閲覧できてはいけない
- いずれのお客様でもセキュリティインシデントは本当にクリティカルであるため、安心安全に利用いただくためにマルチテナント環境においてRLS(Row Level Security)という仕組みを導入して他組織の情報をミドルウェアレイヤーで閲覧できないようにするなどデータの取り扱いはとても慎重に行っている(一般的にRLSはその特性から性能問題が出やすいと言われており弊社も戦ってきました) 参考:https://tech.beatrust.com/entry/rls-nestjs-prisma2
具体的なKAIZEN内容
そしてやっと本題なのですが、障害への取り組みとして以下3点を進めてきました。
- リリースプロセスの整備
- 障害発生から収束までのプロセスの整備
- 大規模ユーザー環境の構築
リリースプロセスの整備
もともと検証のプロセスはありましたが、現時点では以下のようなプロセスを整備して障害を未然に防ぎつつ、週に数回リリースを行える体制を構築しています。コードレビューが通ったPRで開発者が検証環境で検証可能(=リリース準備完了)となったものにLGTMラベルを貼りまとめて日々最終検証をしているのですが、その手前の開発者用検証環境は重要で、検証環境での検証で大きな改修やバグが発生すると差し戻しとなりリリースサイクルが長くなってしまうため、検証環境は最終確認の場としつつ大きなFeatureは事前に使い勝手含めた検証を行いやすくするための環境として構築しています。

- 大きなFeatureの場合、開発者用の検証環境にdeployしてPdMや関係者に動作確認を依頼して操作感や仕様などの認識の齟齬がないか確認する
- 小さなFeatureであったり1が問題ない場合、開発者はPRを作成してGitHub上でreviewerを1名以上指定する(大きなPRをリリース可能な複数のPRに分割して出したりFeature Flagを実装して一部組織のみに限定 Releaseする場合もあります)
- PR作成者は、reviewerのコードレビュー結果がApproveとなり改めてリリース可能と判断したPRにLGTMのラベルをつける
- リリース担当者は、LGTMのラベルを付けているものをまとめたrelease branchのPRを作成する
- 検証環境で最終的な結合テスト+品質チェック+Autifyでの動作確認を行い、リリースPRの検証内容がApproveとなったら適切なタイミングで本番にリリースする
CI/CDにはGitHub Actionsを利用していますが、4と5の検証環境&本番へのdeployは自動で行われるようにしており、以下のワークフローを構築しています。
- release/xxxのブランチがPUSHされると検証環境にdeployされる
- masterブランチにmergeされたら本番環境にdeployされる
また、新しいcommitがPUSHされた際にはUTやE2Eテストが実行され、それらがすべて通っていてかつApproveとなったPRしかmergeできない仕組みとしています。
リリースプロセスの整備としては、2021年初期の障害の状況を受け、第三者検証・品質保証を得意とする会社さんにも関わってもらいテストシナリオの整備や大きなリリースの際の検証をお願いするなどもしていました。また、今回の整備とは別にはなりますがセキュリティ強化のために別途年に1回以上外部のセキュリティ会社にセキュリティ上のリスクが無いかの検証を依頼しています。
現状、自動テストの専任担当者はいないため複数環境(IE含む)での検証ができるAutifyというNoCodeのテストツールを導入してなんとかメンテナンスしております。
障害発生から収束までのプロセスKAIZEN
ISMS取得のために障害発生時の連絡プロセス自体は整備していたのですが、障害が多発した際に対応が後手となり、どう迅速にチームで連携して再発防止に取り組むかはKAIZENポイントでした。 一度、全社まきこんで過去発生した障害の傾向分析や根本対策を行い、現在は以下のプロセスで進むようになっています。
- お客さま・社内・alert channelなどどこかから障害の種を検知する(発生した例外はSentryを経由して、ないしはlatencyなどの監視項目がしきい値を超えた際には #alert_beatrustというslack channelに通知が飛ぶ)
- 早急に対応が必要と判断したら特定の名前の #incident_xxx というchannelを作成し社員全員(2021/12末時点で13名)と関係者を追加する
- @channel で全員に対して現状サマリを伝えて、主にDevチームは影響範囲の特定や問題の暫定 or 恒久対応、Bizチーム&PdMはお客さまへの連絡方針・方法を整備する
- 問題が継続しそうか・収束しそう/したかなど状況に応じて3で決めた方針に従い対象者に連絡する
- 障害が収束したらNotionに障害レポートを作成して今後の対策を整備する
- 障害内容の周知&振り返りを行った後に2で作成したincident channelをArchiveする
※過去発生はしていませんが、情報漏えいを含む情報セキュリティインシデントが発生した場合には緊急事態としてSlackでの通知だけではなくCEO/PdM/EMの誰かをたたき起こすプロセスにしています。
大規模ユーザーへの取り組み
ユーザー数はこの1年で1,000名から10,000名まで10倍の成長を遂げることができました。
しかしその過程で、アーキテクトとしては考慮・準備不足なのですが、過去最大規模の2倍以上のユーザー数で開始するお客さまが発生した際に負荷まわりの課題が発生してしまいました。具体的にはメルマガ配信の際にOOMが発生したり、SendGridに短期間で大量のメール送信依頼をしたことでconnection timeoutが発生するようになり(後者はSendGridにも問い合わせましたが”再送して”とのことでした)、非同期で分割して依頼する仕組みを構築したり再実行させるロジックを入れるなどして適宜対応してきました。
障害対応のふり返りの中で、2022年にさらに多くのユーザーが入ってきた際にお客さまが利用しだしてから対応し出しては間に合わなくなるため、大規模ユーザー検証環境を事前に構築して課題を洗い出して先行して対応していこうというプロジェクトが発足して対応を進めています。
具体的には、1組織で仮に10万ユーザーが利用することになった際にもUXとして大きな劣後が発生しないか・負荷に耐えられるかを事前に検証できる大規模ユーザー環境を検証環境内に構築しています。
- データ数増による本番他組織への影響のリスクを考慮し本番環境ではなく検証用環境に構築
- テストデータは再投入できるようにスクリプト化して、あまりにもランダムなデータだと意味も薄くなるため分布や登録データもそれっぽいデータを構築(=実際に近いデータで環境を整備)
- 10万ユーザーのうち4名は異常にデータ数が多いヘビーユーザーを意図的に作成
実際、環境を構築してみたところいくつか速度周り含めた課題も発見できており2022年の業務はそのあたりのチューニングからスタートします。大規模環境が整ったことで10万ユーザーもいる際にUXの品質向上に取り組むことができ、どのあたりがボトルネックになりそうか、事前に確認できるようになったかと思います。
現状とこれから
過去はオペレーションまわりでも不手際がありましたが、外部の会社にも各種整備を手伝ってもらいつつ、日々増えるユーザの期待に応えるべく各種環境を整備し、最近は検証漏れ(考慮しきれなかったバグが本番環境に出てしまう)やユーザー増加による負荷に備えるフェーズに変わってきたかなと考えています。
障害0という夢の世界線を目指しつつ、現在のプロダクト開発チームの状況としては以下のようになってきたとは感じています。
- 障害0件が継続的に維持できている状態でないのは事実ですが、チームで迅速に対応できるようになり、障害発生時に該当Channelに自然と情報が集約されるようになった
- 収束した障害に関してもポストモーテムとしてどんなKAIZENがシステムに必要か振り返り、再発しないよう・よりよい体験を提供できるような開発体制が整ってきた
また、障害発生後にSales/CSのみなさんと連携して迅速に対象者に連絡し短期間で収束した件について、その動きを見てくれていた企業ご担当者さまより、”(その各種対応によって)むしろ信頼が増した”というフィードバックもありました、ありがとうございます。
最初に述べたように弊社はまだPMFを目指しているフェーズのため、スピードを重視しつつ品質とのバランスをとって進めているスタートアップの1社です。しかし品質を疎かにすると障害に対して後手となりスピードは低下しますし、何よりもユーザーの信頼が大きく低下すると考えています。我々の提供したいUXとして品質向上やKAIZENは命題の一つであり、2022年も継続的に取り組んでいきます。
Beatrustの価値を感じてくれているユーザーインタビューが増えてきたという実感もあり、2022年は10,000ユーザーから100,000ユーザー、さらに多くのユーザーに価値提供すべく10x以上の成長にトライしていきます。
こちらを読んで興味を持っていただいたエンジニアさんや、エンタープライズ向けのプロダクト・ユーザ増加に対する負荷が大好物という方など弊社に興味を持っていただいた方がおりましたら、ぜひ以下よりお声がけいただけましたら幸甚です。
本記事を読んで品質やプロダクト開発に関する情報交換に興味持っていただいた方も是非と考えておりますので、TwitterのDMなどでも気軽にご連絡いただけましたら幸いです!!