
Overview of this Part
In the previous sections, we discussed the importance of evaluating RAG and introduced the calculation methods used in Ragas, a library for automated RAG evaluation. In this part, in order to examine the usefulness of Ragas, I (Hirokazu Suzuki) will quantitatively assess how closely the numerical values of Ragas' evaluations align with my manually assigned scores.
- RAG Evaluation: Necessity and Challenge
- RAG Evaluation: RAG Metrics and Calculation Methods in Ragas
- RAG Evaluation: Assessing the Usefulness of Ragas (This Part)
Experiment on Evaluating Ragas
In order to assess how useful Ragas is in practice, I quantitatively assessed how colse the Ragas results were to my own intuition.
Procedure
After manually creating a unique dataset for evaluation, I tested the validity of Ragas by comparing the metrics calculated by Ragas with my own evaluation scores. For reference, I also evaluated the Correctness by LangChain in the same way.
Dataset Overview
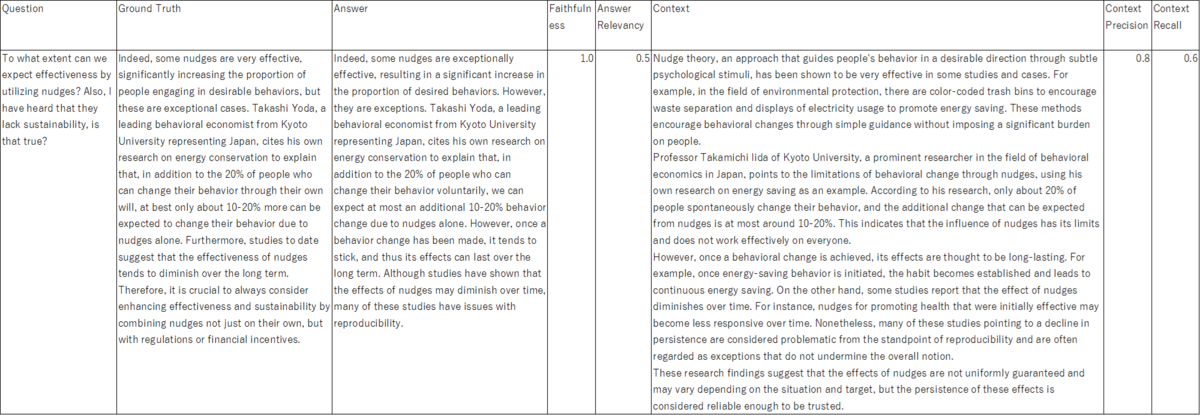
The dataset I used this experiment was not from Beatrust due to data security reasons, but was created based on my personal interest in behavioral economics and nudges (Figures 3-2 show specific examples).
The dataset consists of 50 pairs of four elements; question, true answer (ground truth), answer, and context. The questions and true answers were manually created by me, selecting sources like this page as the contexts. The answers were not created by LLMs but by me manually and deliberately adding and subtracting information based on the true answers. This is because I want to assess Ragas approproately. For the purpose of verifying differences in scores between languages, I also created a dataset in English that was created in Japanese and then mechanically translated by GPT-4 (gpt-4-1106-preview).
Evaluation by Ragas
Evaluations included:
- Evaluation of Generation
- Faithfulness
- Answer Relevancy
- Evaluation of Retrieval
- Context Precision
- Context Recall
and also the end-to-end evaluation of Answer Correctness was adopted (details can be found here), and compared it with the Correctness by LangChain. Additionally, to test how much the scores are affected by differences in the LLM models, the evaluation was conducted using two LLM models: GPT-3.5 (gpt-3.5-turbo-1106) and GPT-4 (gpt-4-1106-preview). Note that the Ragas version is 0.0.22, and LangChain version is 0.1.9.
Manual Evaluation
To see how closely the scores by Ragas matched my intuition, I manually assigned evaluation scores based on the following criteria aligned with the Ragas metric concepts. Although there were criteria such as how much relevance was acceptable, I assigned scores reflecting my expectations when I use them in practice.
| Ragas Metric | Manual Evaluation Criteria |
|---|---|
| Faithfulness | How relevant the answer is to the context |
| Answer Relevancy | How relevant the answer is to the question |
| Context Precision | How relevant the context is to the question |
| Context Recall | How relevant the context is to the Ground Truth |
Figure 3-1 Overview of Manual Evaluation Criteria
Comparison of Ragas Metrics and Manual Evaluation
For the comparison between Ragas metrics and manual evaluation, Pearson's correlation coefficient was used.
Experiment Results
The correlation coefficients between Ragas' evaluation metrics and manual evaluation are as shown in Figure 3-3.
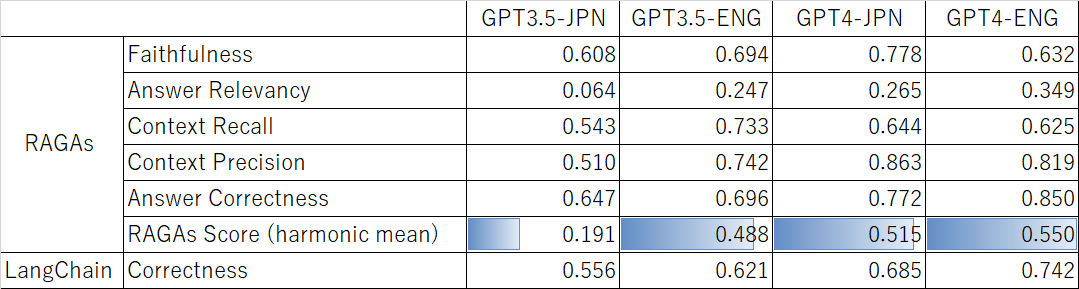
According to the harmonic mean (Ragas score), the results can be interpreted as GPT3.5-JPN<<GPT3.5-ENG<GPT4-JPN<<GPT4-ENG. The lower evaluation of GPT3.5 in the Japanese dataset suggests that:
- Ragas has higher evaluation capabilities for English data.
- GPT4 has higher evaluation capabilities.
The fact that GPT4 outperformed all languages in GPT3.5 suggests that the impact of using GPT4 is greater than the difference in languages.
Additionally, comparing Ragas' Answer Correctness with LangChain's Correctness, the correlation coefficient with the former is consistently higher, suggesting that Ragas is superior as an end-to-end evaluation.
Discussion
Advantages of Ragas
End-to-End Evaluation
As mentioned earlier, the result showed that Ragas outperformed LangChain in end-to-end evaluation, which is considered superior. This is because LangChain calculates a score of 0 or 1, while Ragas calculates scores between 0 and 1, allowing for partial correctness judgments.
Challenges for Ragas
Lower Correlation Coefficients than Expected
In terms of LLM evaluation, the correlation coefficients between Ragas metrics and manual evaluation remained at a harmonic mean of 0.55 at best. Individual metrics such as Context Precision and Answer Correctness scored high in the GPT4-ENG case with 0.82 and 0.85, respectively, but even so, they are not at a level to be blindly trusted in practice. While there was an expectation that Ragas could mechanically perform RAG evaluations, this experiment suggests that manual evaluation is still essential.
Below, we discuss the reasons why particularly low values were obtained for Faithfulness and Answer Relevancy.
Cause 1: Overestimation of Faithfulness
Faithfulness is a metric that measures how relevant a generated answer is to the context.
It has been observed that high scores tend to be calculated even if the generated answer is based only on a part of the context and does not reflect the entire context (Figure 3-4 for illustration). For example, consider a context consisting of four paragraphs: a common theory, a possible rebuttal, a rebuttal to that rebuttal, and a conclusion. If the answer only pulls from the possible rebuttal, it is hard to say it reflects the entire context. In this case, Faithfulness would still calculate as 1.0, resulting in overestimation, which is problematic because it deviates from human perception.

As an example, in this experiment, we observed the following case (Figure 3-5): "How much budget is needed to implement nudges in administration?" The context and answer are derived only from the initial part of the context. While I rated it as reflecting about half of the important content in the context with a score of 0.6, Ragas calculated a score of 1.0 for all models and languages.

Cause 2: Variability in Answer Relevancy
Answer Relevancy is a metric that indicates how well the LLM's response aligns with the question.
In Figure 3-3, Answer Relevancy particularly had low correlation coefficients. Here, we consider two main reasons for this.
In Ragas, Answer Relevancy is calculated by generating a pseudo-question from the answer and calculating the cosine similarity with the original question. This method seems good because if the answer clearly matches the question, the correlation between the question generated from the answer and the original question will be high.
However, this method uses OpenAI's text-embedding-ada for vectorization, known to not allow the cosine similarity to drop below 0.6 between any two texts, regardless of how similar they are (https://community.openai.com/t/some-questions-about-text-embedding-ada-002-s-embedding/35299). Therefore, while my labels ranged from 0 to 1, Ragas could only output scores between 0.6 and 1, significantly lowering the correlation coefficient.
A potential fix is to subtract the average vector from the generated vectors (https://arxiv.org/abs/1702.01417), which could make the cosine similarity in the vector space more akin to our metrics and increase the utility of Answer Relevancy. However, as shown below, the calculation method that forcibly outputs a zero also distorted the overall distribution, making it difficult to correct with the average vector and unverified.In Ragas, if the LLM deems it "noncommittal," the logic forcibly outputs a zero for Answer Relevancy. The criteria for deciding "noncommittal" were vague, and a significant discrepancy from my judgment also contributed to the low correlation coefficients.
Conclusion
In this blog, we introduced the importance of RAG evaluation and tested the practicality of Ragas, which seemed mechanically feasible. The results obtained from this validation are as follows:
- Ragas is suitable for RAG evaluation as it separates the Generation and Retrieval parts.
- Based on the correlation coefficients, Ragas' end-to-end evaluation was superior to that of LangChain.
- However, Ragas did not achieve as high correlation coefficients as expected.
With the evolution of LLMs, phrases like "RAG might be dead" have started to question the utility of basic, uncustomised RAG. Therefore, whether an objective evaluation method for RAG can be realised is a crucial element in the widespread adoption of RAG. We hope that the industry will place value on evaluation and that research will be actively conducted.
⚠️RAG might be dead, after reading 58 pages of Genimi 1.5 Pro tech report. Here's my thoughts as AI founder,
— Shaun.AGI (@agishaun) 2024年2月16日
1. Simple RAG system like similarity search with vector db will be dead. But more customized RAG will still live. The goal of RAG is mostly on retrieval relevant… pic.twitter.com/G0Prlu1Z11