
- RAG Evaluation: Necessity and Challenge
- RAG Evaluation: RAG Metrics and Calculation Methods in Ragas (This Part)
- RAG Evaluation: Assessing the Usefulness of Ragas
Overview of this Part
In the previous part, Do Not Forget, we discussed the usefulness of automated quantitative evaluation of RAG. In this post, we will focus on the following points:
- Commonly used evaluation metrics for RAG
- The calculation methods of these metrics in Ragas, a library for RAG evaluation
RAG Evaluation: Ragas
For the evaluation of RAG, Faithfulness and Answer Relevancy, which assess generation, and Context Precision and Context Recall, which assess retrieval and acquisition, are mainly used.
Ragas (Retrieval Augmented Generation Assessment) automatically carries out evaluations, which was notably featured at OpenAI's DevDay in November 2023.
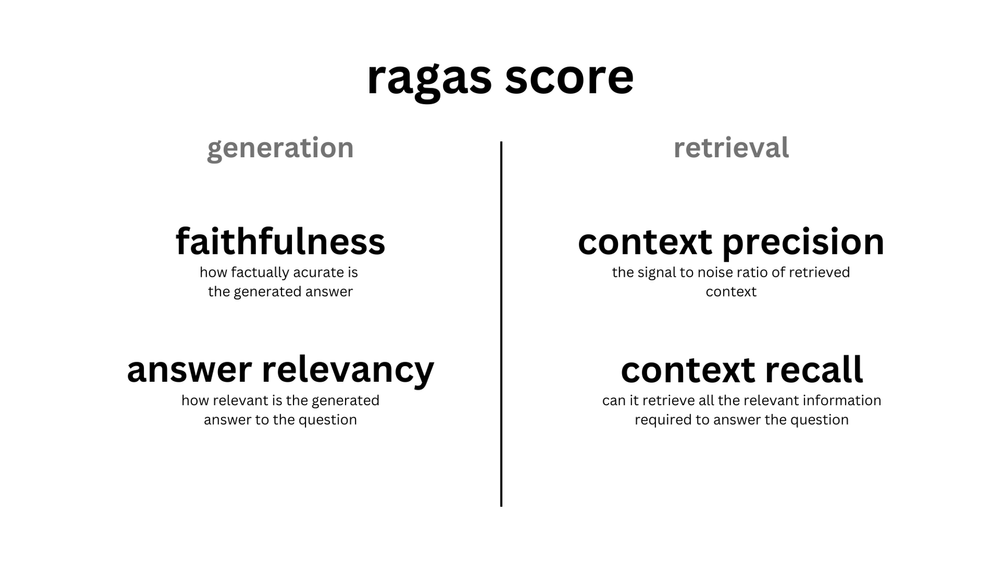
In the following, we will show the calculation methods in Ragas for the common metrics listed in Figure 2-1: Faithfulness, Answer Relevance, Context Precision, and Context Recall (Ragas library version 0.0.22). Ragas also offers various other metrics, and this article will describe Answer Correctness used in our experiments. The context mentioned below refers to the text required to answer a question retrieved from the database by RAG.
Evaluation of Generation
Faithfulness
Overview: Measures how relevant the answers provided by the LLM are to the retrieved context. Scores range from 0 to 1, with higher scores indicating better performance.
Ragas calculates it as follows:
- From the question and generated answer, generate the statements used in the answer using LLM
- Determine the relationship between statements and the contexst using LLM (Yes/No)
- Compute the number of context-relevant statements divided by the total number of statements

Answer Relevance
Overview: Measures how relevant the LLM's answers is to the question. Incomplete or redundant answers receive lower scores. Scores range from 0 to 1, with higher scores indicating better performance.
Ragas calculates it as follows:
- Generate pseudo-questions from the context and the generated answer using LLM
- Calculate the cosine similarity between the original question and the pseudo-question respectively
- Compute the average similarities

Evaluation of Retrieval
Context Precision
Overview: Measures how accurately the LLM retrieves the necessary information (context) for answering the question. Scores range from 0 to 1, with higher scores indicating better performance.
Ragas calculates it as follows:
- Determine the relationship between each retrieved context to the original question using LLM (Yes/No)
- Compute mAP (Mean Average Precision)

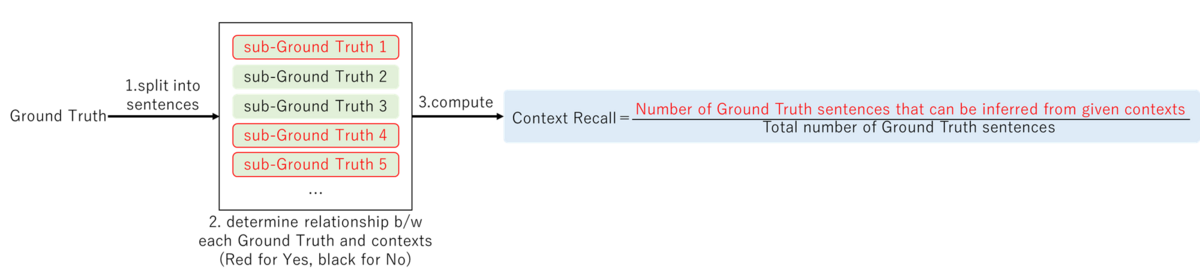
Context Recall
Overview: Measures how much the retrieved context matches the Ground Truth. Scores range from 0 to 1, with higher scores indicating better performance.
Ragas calculates it as follows:
- Split the Ground Truth into sentences
- Determine the relationship between each sub-Ground Truth sentence to the retrieved context using LLM (Yes/No)
- Compute the number of context-relevant Ground Truth sentences divided by the total number of Ground Truth sentences
Other Evaluations
Besides these four metrics, Ragas offers various others, but here we introduce Answer Correctness used in our experiments.
Answer Correctness
Overview: Measures how accurate the generated answer is in comparison to the Ground Truth. Scores range from 0 to 1, with higher scores indicating better performance.
Ragas calculates it as follows:
- Classify the generated answers and Ground Truth into those present in both (TP), only in the answer (FP), and only in the Ground Truth (FN) using LLM.
- Compute a score similar to F1 based on these classifications
- Compute the cosine similarity between the generated answer and the Ground Truth
- Compute a weighted average of the F1-like score and cosine similarity

This concludes our overview of Ragas and the method descriptions for each metric. The next page will explore how RAG is evaluated using Ragas and assess the robustness of the evaluation system for LLMs and languages mentioned previously.