
本パートの概要
前回のパートではRAGの自動での定量評価の有用性について述べさせていただきました。今回は、
- RAGの一般的に用いられる評価指標
- 評価の代表的なライブラリであるRagasで上記評価指標の計算方法
に注目して紹介していきたいと思います!
- RAGの評価:評価の必要性と問題点
- RAGの評価:RAGの計算指標とRagasでの計算方法 (本パート)
- RAGの評価:Ragasの有用性の評価
RAGの評価 : Ragas
RAGの評価には生成を評価するFaithfulnessとAnswer Relevancyと検索・取得を評価するContext PrecisionとContext Recallが主に用いられます。
Ragas(Retrieval augmented generation assessment)とは、これらの評価を機械的に行うものです。2023年11月のOpenAI DevDayでも取り上げられていたことが印象に残っています。
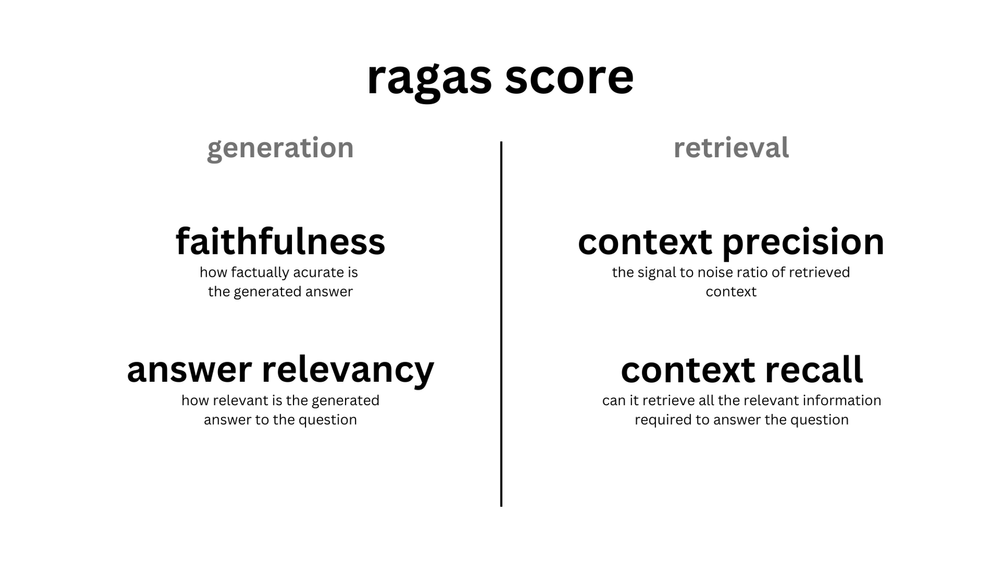
以下では、図表2-1にある一般的な指標であるFaithfulness、Answer Relevance、Context Precision、Context RecallのRagasでの計算方法を紹介していきます(Ragasのライブラリのバージョンは0.0.22)。また、Ragasではこの4つの指標以外にも様々な指標が用意されており、本稿では実験で使用したAnswer Correctnessを説明しています。なお、以下の説明の中で登場するコンテキストとは、RAGによってデータベースから取得した質問の回答に必要になるテキストを指します。
Generationの評価
Faithfulness
概要:LLMがどの程度、取得したコンテキストに関連した回答をしているかを計測。0〜1の値をとり、高いほど良い。
Ragasではこのように計算されてます:
- 質問と生成された回答から、回答に用いられたであろう文章(ステートメント)をLLMで生成
- ステートメントとコンテキストの関連をLLMで判定(Yes/No)
- コンテキストに関連するステートメント数÷全ステートメント数を算出

Answer Relevance
概要:LLMがどの程度質問に沿った回答をしているかを計測。不完全な回答や冗長な情報を含む回答には低いスコアが割り当てられる。0〜1の値をとり、高いほど良い。
Ragasではこのように計算されてます:
- 生成された回答とコンテキストから擬似的な質問をLLMで生成
- 元の質問と生成された疑似質問のコサイン類似度をそれぞれ計算
- 類似度の平均を算出

Retrievalの評価
Context Precision
概要:LLMがどの程度、質問の回答に必要な情報(コンテキスト)を正確に取得しているかを計測。0〜1の値をとり、高いほど良い。
Ragasではこのように計算されてます:
- 元の質問と取得したそれぞれのコンテキストとの関連をLLMで判定(Yes/No)
- mAP(Mean Average Precision)を算出

図表2-4 Context Precisionの計算方法の概要
Context Recall
概要:取得したコンテキストが、どの程度、Ground Truthと一致しているかを計測。0〜1の値をとり、高いほど良い。
Ragasではこのように計算されてます:
- Ground Truthを文単位に分割
- Ground Truthの各文(sub-Ground Truth)と取得したコンテキストとの関連をLLMで判定(Yes/No)
- コンテキストに関連するGround Truthの文の数÷Ground Truthの文の数で算出

その他の評価
以上の4指標のほか、Ragasでは様々な指標が用意されていますが、今回の実験で使用したAnswer Correctnessをここでは紹介します。
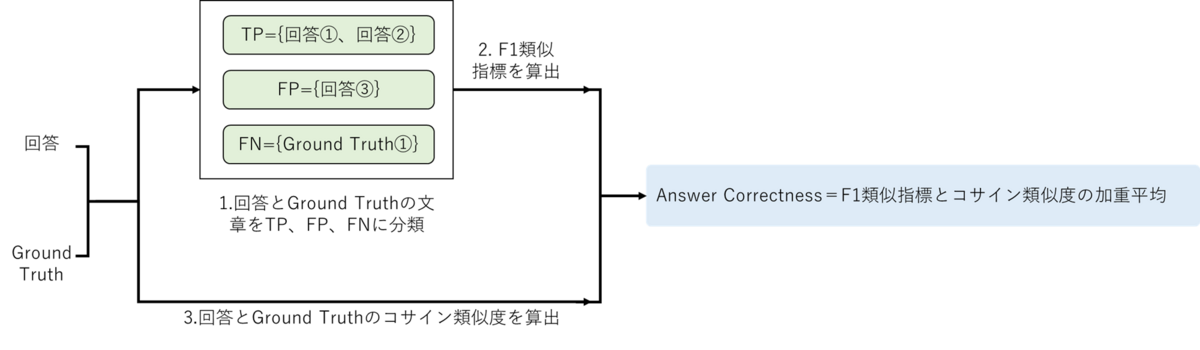
Answer Correctness
概要:生成された回答が、どの程度、Ground Truthに対して正確かを計測。0〜1の値をとり、高いほど良い。
Ragasではこのように計算されてます:
- 生成された回答とGround Truthの文章を、両者に含まれるもの(TP)、回答には含まれるがGround Truthにはないもの(FP)、Ground Truthには含まれるが回答にはないもの(FN)にLLMで分類
- 分類を基に正確性を測るF1に類似したスコアを算出
- 生成された回答とGround Truthのコサイン類似度を算出
- F1類似スコアとコサイン類似度の加重平均を算出
以上、Ragasの概要と、各指標のアルゴリズムの開設になります。
次のパートでは、実際にRagasを使ってRAGがどのように評価されるのか、前ページで述べたLLMや言語に対して評価制度がどの程度頑健なのかを検証していきたいと思います。