
本パートの概要
これまでのパートでRAGの評価の重要性と、自動評価の代表的なライブラリであるRagasにおける計算方法の紹介を行ってきました。本パートでは、私(鈴木)がマニュアルでつけたスコアとRagasの評価の数値をの相関を取ることでRagasの評価値は私の感覚とどれほど近しいものなのかを定量評価し、Ragasの有用性を調べました。
- RAGの評価:評価の必要性と問題点
- RAGの評価:RAGの計算指標とRagasでの計算方法
- RAGの評価:Ragasの有用性の評価 (本パート)
Ragasの評価の実験
この記事では前回紹介したRagasが実際にどれくらい有用なのかを評価するために、Ragasの結果が私の感覚とどれくらい近いのか定量的に評価しました。
手順
評価用の独自のデータセットをマニュアルで作成の上、Ragasによって算出された指標と私の感覚による評価スコアとの対比を通じて、Ragasの妥当性を検証しました。また、参考のため他の評価指標として、LangChainのCorrectnessも同様に評価してみました。
データセットの概要
今回用いたデータセットはデータセキュリティーの観点からBeatrustのものではなく、私が個人的に関心のある行動経済学とナッジに関するものを作成し、それを用いました(図表3−2に具体例を表示)。
データセットは質問、真の回答(ground truth)、回答、コンテキストの4要素からなる50組のペアで構成されています。質問と真の回答は、行動経済学やナッジについて解説している自治体ナッジシェアなどの情報をコンテキストとして選びつつ、私がマニュアルで作成しました。回答は、Ragasが適切に評価が行えているかを確認するために、LLMによるものではなく、私がマニュアルで真の回答をベースに意図的に情報を足したり引いたりしながら作成しています。また、言語間のスコアの差異を検証する目的で、日本語で作成した後、GPT-4(gpt-4-1106-preview)によって機械的に翻訳された英語のデータセットも作成しました。
Ragasによる評価
評価には前回のブログで紹介した
- 生成(Generation)の評価
- Faithfulness
- Answer Relevancy
- 検索・取得(Retrieval)の評価
- Context Precision
- Context Recall
に加え、e2eでの評価 のAnswer Correctnessも採用し(詳細はこちら)、LangChainのCorrectnessとの比較を行いました。また、LLMモデルの差にスコアがどれくらい影響されるのかを検証する目的で、GPT-3.5(gpt-3.5-turbo-1106)とGPT-4(gpt-4-1106-preview)の2つのモデルを用いて評価を行いました。なお、ライブラリのバージョンはそれぞれRagasは0.0.22、LangChainは0.1.9です。
人手による評価
Ragasによるスコアが私の感覚とどれほど似ているのかを確認するため、Ragas指標コンセプトに沿って、以下のような基準で私がマニュアルで評価スコアを付与していきました。関連度合いをどこまで許容するかなどの基準はありましたが、自分が実務で使う場合の期待を反映させる形でスコアをつけました。
| Ragasの指標 | 人手評価の基準 |
|---|---|
| Faithfulness | 回答がコンテキストに対してどれだけ関連しているか |
| Answer Relevancy | 回答が質問に対してどれだけ関連しているか |
| Context Precision | コンテキストが質問に対してどれだけ関連しているか |
| Context Recall | コンテキストがGround Truthに対してどれだけ関連しているか |
図表 3−1 人手評価の基準の概要

Ragas指標と人手評価の比較等
Ragas指標と人手評価の比較には、ピアソンの相関係数を用いました。
実験結果
Ragasによる評価指標と人手評価との相関係数は図表3-3のとおりとなりました。
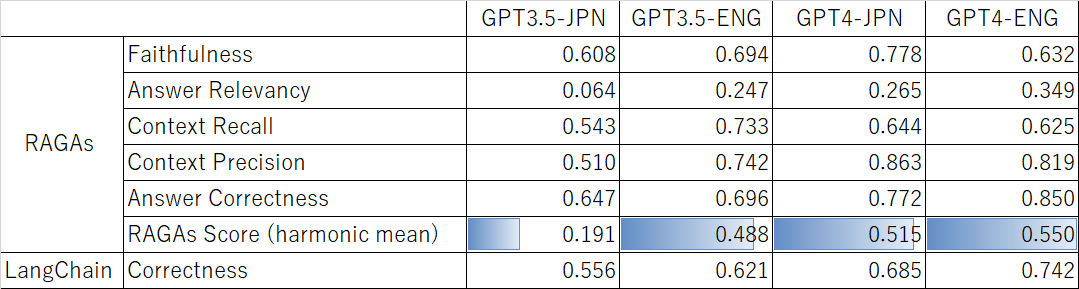
Ragasの調和平均 (Ragas score)によれば、GPT3.5-JPN<<GPT3.5-ENG<GPT4-JPN<<GPT4-ENGという結果になったと見ることができそうです。日本語データセットでのGPT3.5評価が低くなっていることから、今回の実験結果から
- Ragasは英語のデータのほうが評価能力が高い
- GPT4の方が評価能力が高い
ということが推察されました。GPT4がGPT3.5のすべての言語より高いスコアを出したことから、GPT4を使うインパクトは言語の差より大きいと感じました。
また、RagasのAnswer CorrectnessとLangChainのCorrectnessを比較すると、前者との相関係数が常に高いことから、e2eの評価としてはRagasの方が優れていると言えそうです。
考察
Ragasの利点
e2eでの評価
先述のとおり、e2e評価としてはLangChainよりRagasの方が優れているとの結果が得られました。これはLangChainのCorrectnessが0か1かのスコアを算出するのに対し、Ragasが0〜1の間でのスコアを算出し、部分的な正誤の判断が可能であったためと思われます。
Ragasの課題
期待していたほどの相関係数の数値が得られなかった
LLMの評価について、Ragas指標と人手評価との相関係数は、高くても調和平均で0.55という結果に留まりました。個別の指標ではContext PrecisionやAnswer CorrectnessがGPT4-ENGのケースで0.82や0.85と高スコアを出しましたが、それでも、実務においては盲目的に信頼するレベルには達していないのではないかと感じます。Ragasを使用することでRAG評価が機械的に行えるのではないかという期待もありましたが、今回の実験では、やはり人手による評価が不可欠であるという結果が示唆されたのではないかと思われます。
以下では、特に相関係数が低い値となったFaithfullnessとAnswer Relevancyを取り上げて、このようになった理由を考察してみました
原因1 : Faithfullnessの過大評価
Faithfullnessは生成された回答とコンテキストの関連度合いを測定する指標です。
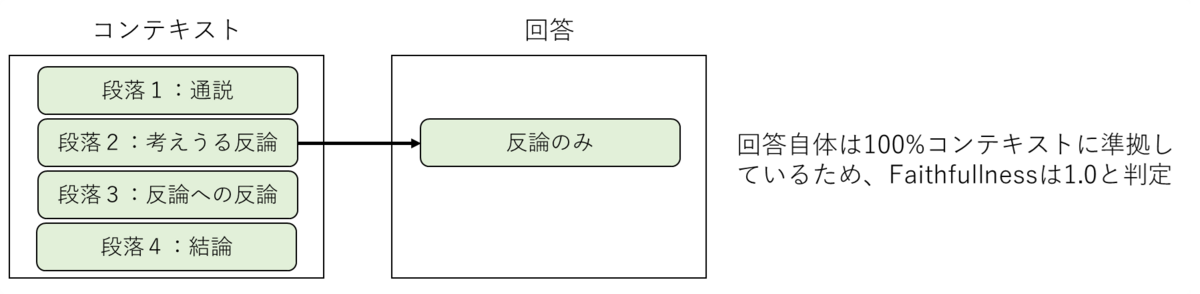
生成された回答がコンテキスト一部のみに基づき、コンテキスト全体を反映していない場合でも高いスコアが算出される傾向があることが観察できました (図3−4に例示)。例えば、通説、考えうる反論、反論への反論、結論という4つの段落からなるコンテキストがあり、回答はそのうち考えうる反論のみを引っ張ってきた場合を考えたいと思います。考えうる反論はコンテキスト全体の意見を反映しているとは言い難いですが、この場合でもFaithfullnessは1.0と算出されてしまい、過大評価されてしまうという問題があります。
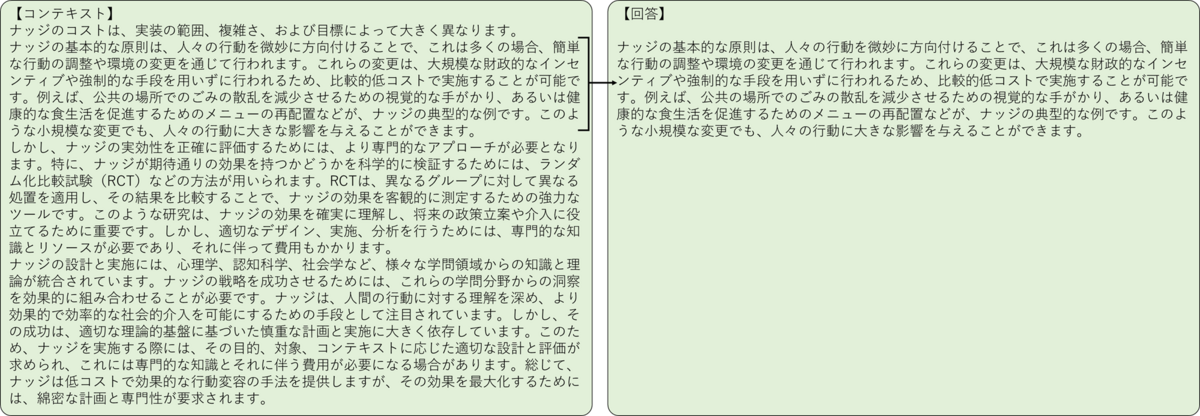
例として、今回の実験では以下のような事例が見られました (図3-5 )。「行政においてナッジを実施するにはどの程度予算が必要でしょうか。」という質問に対するコンテキストと回答になります。回答はコンテキストの前段の一部分のみを引っ張ってきている形になっているため、私としてはコンテキストで大事な内容の半分程度が反映されているため0.6としたのですが、Ragasではいずれのモデル・言語でも1.0が算出されていました。
原因2 : Answer Relevancyのばらつき
Answer RelevancyはLLMがどの程度質問に沿った回答をしているかの指標です。
図表3-3の中でもAnswer Relevancyは特に低い相関係数になりました。ここではその主原因として考えられる2点を考察します。
Ragasでは、Answer Relevancyは回答から疑似質問を生成し、元の質問とのコサイン類似度を計算することで算出されています。この方法では確かに、質問に沿ったクリアな回答をしていれば、回答から生成した質問と元の質問の相関が高くなるので、良い計算方法に思えます。
一方、この方法では、ベクトル化にOpenAIのtext-embedding-adaを用いてますが、これでは、どんなに似なる2つの文章でも最大で0.6までしかコサイン類似度が下がらないことが知られています。(https://community.openai.com/t/some-questions-about-text-embedding-ada-002-s-embedding/35299)。なので、私のラベルでは、0~1の間でラベルしてましたが、Ragasでは0.6~1の間でしか、スコアを出すことができません。これが相関係数を下げた大きな原因だと考えております。
これの対策として、生成されたベクトルから、平均ベクトルを引く工夫をすること(https://arxiv.org/abs/1702.01417)で、ベクトル空間におけるコサイン類似度が我々の指標に似たものになり、Answer Relevancyの有用性も上昇すると考えています。ただし、以下のように、無理やり0を算出する計算方法にもなっており、全体として分布が歪んでしまっていたため、平均ベクトルによる修正は難しくなっており、検証しきれませんでした。Ragasでは、"計算不可能"(noncommittal)とLLMが判断した場合、Answer Relevancyを無理やり0を算出するようなロジックになっていました。この"計算不可能"と判断する基準が曖昧で、私と大きくずれていたことも相関係数が低い原因にもなっていました。
まとめ
本ブログでは、RAGの評価の重要性の紹介とそれが機械的にできそうなRagasの実用性を検証しました。この検証で得られた結果は以下のとおりです。
- RagasはGeneration部分とRetrival部分を分けて評価できるのでRAG評価に適していると感じた。
- 相関係数を基準に考えるとLangChainの評価より、Ragasのe2e評価のほうが優れていた。
- 一方、Ragasも期待ほど高い相関係数を得られるわけではなかった。
LLMの進化により、"RAG might be dead"などと表現されるように、カスタマイズされていない基本的なRAGはその有用性に疑問符がつけられ始めています。だからこそ、RAGの客観的の評価手法が実現するかどうかは、RAG普及における重要な要素だと考えています。業界全体で評価に値付けをおき、研究が盛んに行われることを期待します。
⚠️RAG might be dead, after reading 58 pages of Genimi 1.5 Pro tech report. Here's my thoughts as AI founder,
— Shaun.AGI (@agishaun) 2024年2月16日
1. Simple RAG system like similarity search with vector db will be dead. But more customized RAG will still live. The goal of RAG is mostly on retrieval relevant… pic.twitter.com/G0Prlu1Z11