Beatrust で SRE をやっている Yuta(中川 裕太)です.運用がラクにできように色々と改善したり,セキュリティ向上したり,インフラ作ったり API 開発したりしています. 今回のブログでは,Google App Engine (GAE) から Google Kubernetes Engine (GKE) Autopliot へ移行し半年間運用してみて感じたメリットやハマりポイントについて紹介します.
モチベーション
Beatrust では初期立ち上げの開発コストを下げるため,もともと GAE を用いて開発運用してきました.様々なお客様にご利用いただく中で,嬉しいことに今後 10 倍,100 倍のユーザ数成長が見込めるようになってきました.そういった状況下で以下のような GAE の課題も顕在化しており,インフラの抜本的見直しを実施する必要がありました.
- GAE では Auto Scaling がうまく動かないことがたまにあり,原因究明も難しかった点からユーザ数の成長に対して不安感があった.
- 過去に発生したインフラ障害のほとんどが Cloud SQL への接続に用いている Auth proxy 関連のもの (パケロスなど) で,詳細も GCP のサポートに問い合わせないと分からないため非常にしんどかった.
これらの課題を解決するためだけであれば GAE の構成を再検討したり,Cloud Run を用いるなども選択肢としてはありえましたが,Kubernetes のエコシステムは充実しておりそれらを用いて開発運用することで様々な学びを得られるだろう点やイケてる SRE を採用できるだろう点から GKE を採用することにしました.何よりも Kubernetes をちゃんと使うの楽しそうという要素も大きかったです. とはいえ,まだ片手で数えられるほどの開発メンバーしかいない Beatrust にとっては運用コストをなるべく下げたかったため,事前検証を経て GKE Autopilot を採用することにしました.
GKE Autopilot を用いたアーキテクチャ
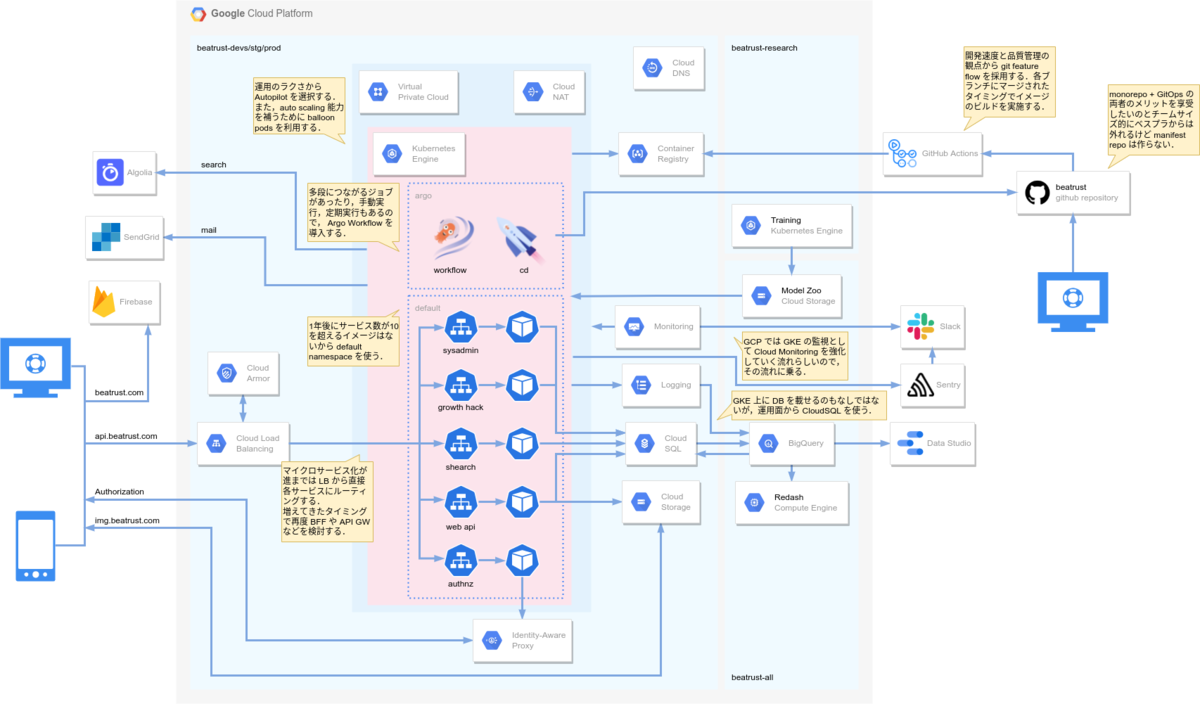
GKE Autopilot を用いたユースケースではバッチの事例が多く,Beatrust のようないわゆる web サービスに求められる Auto Scaling が可能であるかについて懸念がありました.そこで,事前に開発環境にて当初の 10 倍負荷をかけて問題なく Auto Scale できるかについて検証しました.結果としては,Balloon Pods を用いることで高速な Auto Scaling が可能であることが分かり,本格的に GKE Autopilot によるインフラ刷新に取り掛かりました.最終的には HPA のしきい値を低めに設定し Balloon Pods を用いることで性能目標を達成することができました. また,開発環境ではコストを抑えるために Spot VM を用いています.
これらの工夫をすることで,ほぼ運用負荷なく可用性も高い状態で運用できていることはすごいことだと感じています.GAE の Auto Scaling をちゃんとチューニングしたわけではないのでフェアな比較にはなっていませんが,余剰な Balloon Pods を持ちつつ HPA のしきい値を下げた状態でも GAE で運用していたころと比較してコストが実は下がっており,この点でも GKE Autopilot に移行してよかったと感じています.
Autopilot でのハマりポイント
上記のような工夫だけでかなりラクに運用できている GKE Autopilot ですが,開発初期はいくつかのハマりポイントを踏んでいました.それらについて紹介していきます.
Workload Identity の設定が必須
GKE Autopilot のクラスタ上でアプリケーションをとりあえず動かす段階までは比較的容易に構築することができたのですが,一般的な GKE の発想で,デフォルトの Cloud Engine のサービスアカウントとかが認証で使われるのかなと勘違いしており,Cloud Logging など GCP 上のリソースと連携しようとするとエラーが発生してしまうという事象にハマってしまいました. ドキュメントを読めば確かに分かることなのですが,Autopilot では Workload Identity が事前構築されており,Kubernetes と GCP の両方のサービスアカウントに設定をする必要があり,この点は Autopilot を使う上でのハマりポイントでした.
さらに,自身で構築したアプリケーションなどでは意識できますが,例えば,Prometheus を構築した際は,Autopilot では Workload Identity の設定が必須になることを頭では理解しつつ,サンプルを動かした時に権限エラーで正しく動作しなかった時は調査にしばらく時間を使ってしまいました.ここでも最終的には Prometheus で使っているデフォルトのサービスアカウントに Workload Identity を設定してあげることで解決できました.
管理面については Kubernetes と GCP の両方のサービスアカウントに Workload Identity を設定する必要があるので,Config Connector を用いて 1 コの manifest にまとめた方がキレイかなと思いつつ,Autopilot では Config Connector をサポートしていないため manifest と terraform の両者で Workload Identity を設定するというやや面倒くさい方法を取らざるを得ない形になっています.
manifest
apiVersion: v1 kind: ServiceAccount metadata: name: sa annotations: iam.gke.io/gcp-service-account: web-api@beatrust-devs.iam.gserviceaccount.com
terraform
resource "google_service_account" "web_api" { account_id = "web-api" } resource "google_service_account_iam_binding" "web_api_workload_identity" { service_account_id = google_service_account.web_api.name role = "roles/iam.workloadIdentityUser" members = [ "serviceAccount:${local.project_id}.svc.id.goog[default/web-api-sa]" ] }
Autopilot が勝手にリソースを書き換える
続いてハマったポイントは Autopilot が勝手にリソースの値を書き換えるというものです.主にパフォーマンスチューニングをしている際,たまに「性能出ないなぁ」と思ってデプロイされたリソースを見てみると意図したリソースと異なっていたということがありました.調査してみると,Autopilot の制約 を満たさないリソース指定がされると Autopilot が勝手に値を書き換えてしまうということが分かりました.特にワーニングを出すこともなく勝手にリソースの値が書き換わってしまうため,そこそこ初見殺しで苦労しました.
また,Argo CD でリソースを管理している場合には,manifest に書かれている値が Autopilot の制約を満たさないと常に out of sync になってしまうなども発生しました.
将来的には Autopilot の制約に従っているかをチェックできるような linter を開発し CI の中に組み込んでいくことで意図しないリソースになったり Argo CD で out of sync になってしまう事象が発生しにくいようにしていこうと考えています.
未サポートなエコシステムが多い
最後は Kubernetes エコシステムのサポートについてです.少なくとも GKE Autopilot を構築した当初は Istio や Prometheus,Argo 系など Control Plane に近い部分を触る必要があるエコシステムは軒並み未サポートでした.例えば,Argo Workflow では containerRuntimeExecutor を emissary にすることで GKE Autopilot でも利用できるなど一部回避方法が存在するものもありましたが,その他のものについては GKE Autopilot 側でのサポートを待つ必要があるという状況でした.特に構築して正しく動作しなかった際に自分たちの設定ミスなのか,単純に GKE Autopilot が未サポートなのかを切り分けることが難しく苦労しました.しかし,GKE に関しては GCP のサポート対応も親切で「このエコシステムは GKE Autopilot でサポートしていますか」などの質問にちゃんと回答いただけた点は非常によかったです.やっぱり GCP が力を入れているサービスはサポートが充実していてよいですね.
GKE Autopilot 側での対応を座して待ちつつ,対応がされたら取り込んでいくという進め方をせざるを得ませんでしたが,少なくとも現状では Prometheus,Argo CD,Argo Workflow は普通に使えているので今後このハマりポイントを踏む人は少なくなっていくんだろうなとは感じています.
まとめ
GAE から GKE Autopilot に移行して当初の性能目標を達成することができ,コストも GAE よりも下げることができました.Autopilot だからこそのハマりポイントは構築初期こそ踏み苦労はしましたが,特に Workload Identity まわりに慣れれば問題はなく,構築後の運用では半年間で特に大きな問題は発生していません.モニタリングやアラートを追加したりなど運用をラクにする変更は随時加えていますが,それ以外には特に運用タスクが発生することなく,GKE Autopilot 起因の障害も 1 件も発生していないことは GKE Autopilot に移行して非常によかったなと感じています.
構築し始めた当初は,まだ小さいスタートアップで Kubernetes を使いこなせるだろうかと心配していましたが,やってみればハマりポイントはあったものの比較的簡単に構築でき,エコシステムを通じての学びが深く非常に楽しく開発運用できています.今回の経験を経て,GKE Autopilot を使えば小さな組織でも充分に Kubernetes とそのエコシステムの恩恵を授かれるということが分かったので,オススメしたいなと感じました.
BtoB SaaS に求められる非機能を満たしつつ,一緒に楽しくわいわい新しいことにチャレンジする仲間を募集中です!