Beatrust の ML Lead の Tatsuya(白川 達也)です。
機械学習はデータからの学習プロセスを経てデータに最適化した機能を提供する技術ですが、新しい機能の導入前の段階ではユーザーの行動ログデータなどが蓄積されていないため、機械学習ベースの機能を新規提供することには本質的な困難さがあります。
本記事は、Beatrust People における Tag Suggestion 機能を例に、そのような状況においてどのように機械学習ベースの機能を構築していったのかを記したものです。
本記事で書いたこと
- Beatrust における Tag Suggestion 機能の紹介
- データがない状況でどうあがいたか
- 機能改善ポイント(Relevance、Importance、Diversity)
- 仲間を募集しています!
なお、今回の記事は私のほかにもいつも Beatrust を手伝ってくれている仲間・友人たちとの共同の成果でもあります。ありがとうございました!
Tag Suggestion

あなたの人となりをあらわす最適なタグのセットは何でしょう?
Beatrust ではユーザーのプロフィールデータを蓄積・整理し、活用可能にすることを目的としたサービスである Beatrust People と、Beatrust People を基軸にして人や組織のコラボレーションを活性化させるためのサービス群を開発しています。
人材可視化サービスを導入した経験のある方や Beatrust のユーザーにヒアリングをしている中で、プロフィールを更新性に課題を持たれているという声をしばしばお聞きしています。この課題を解決するために、Beatrust ではスキルや興味・趣味の自動抽出・推薦機能の開発に力を入れています。Beatrust のサービス上で発生するデータも含め、Beatrust のユーザーが日々発信しているデータから、その方がどのようなことが得意で何に興味を持っているかなどを抽出・推定し推薦することで、プロフィールの更新の手間を最小限にしつつ、自己認識をより深めてもらおうという機能です。
Tag Suggestion 機能は自動抽出・推薦機能のひとつであり、Beatrust People のプロフィールページ内のタグ情報(その人を端的に表す情報)の編集時に、その人にふさわしそうなタグをリアルタイム推薦する機能になります。下記は Tag Suggestion 機能のイメージ図です。

Beatrust People のイメージを掴んで頂く為に、参考までに私のプロフィールの一部を載せておきます。
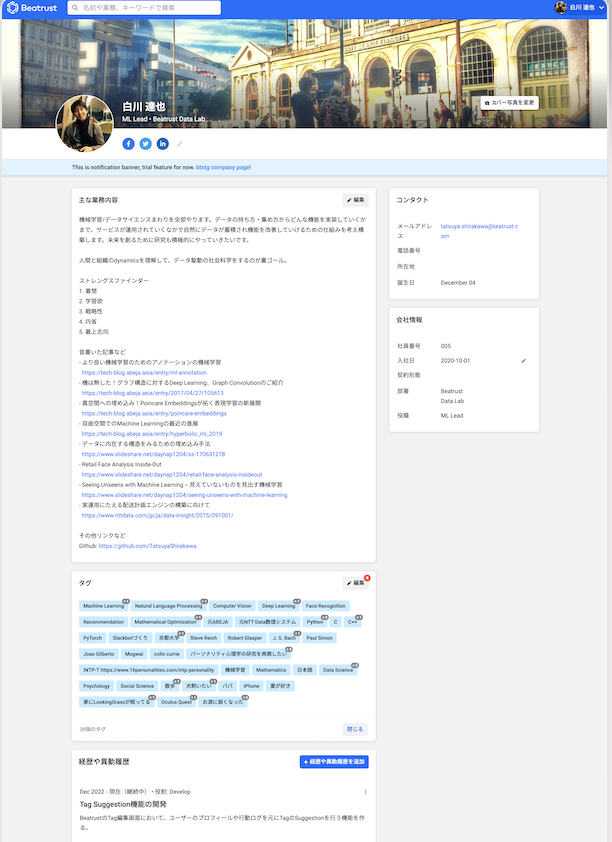
Beatrust は従業員のためのサービスを目指していることもあり、ユーザーのプロフィールには、スキルや資格以外の趣味や興味、ライフスタイルに関連したタグも多く追加される特徴があります。趣味や興味のような、必ずしも仕事上で必要とならないかもしれない情報に関するタグも、たまたま共通点を見つけることをきっかけに深いつながりが生まれたりすることもあるので、実は思いの外重要だったりします。かくいう私も Beatrust に入社にあたって、先に入社していたとある人物と出生地が徒歩圏内レベルで近いことが発覚し、一気に心の距離感が縮まった経験があります。

というわけで、その人を表すさまざまなタグをできるだけ入力しておくことは重要と考えています(一方で増えすぎたタグをどう構造化していくかはこれから解決しないといけない面白い課題です)。ただ、自分のことは案外気づかないもので、自分にどんなタグを付けられるのかが分からないとか、自分をよく表すタグであっても誰かに指摘されるまで気づかないというのはしばしばユーザーから上がってくる声でした。
そのため、その人の発信した情報からその人に関する情報を客観的に抽出・予測し、推薦してあげる Tag Suggestion 機能は Beatrust People にとって本質的に重要な機能と捉えています。
下記は Tag Suggestion 機能の Feature Doc で定義された UI デザインです。

Beatrust では、それなりの粒度の機能を作る際には、機能への想いと要件を込めた Feature Doc というドキュメントを作成し、それをもとに機能作成をしていきます。上記のデザインにおける Tags ボックス中の "New tags recommended for you" の部分に表示されている Tag を、ユーザーのプロフィール情報や追加したタグ情報と連動してリアルタイムに計算するのが Tag Suggestion 機能におけるロジックの役割となります。
Tag Suggestion の難しさ
Beatrust は創業間もないにも関わらず、ありがたいことに複数の業界の企業様にすでにご利用いただけております。これはとても(本当に!)嬉しい一方で、業界・企業固有の語彙を踏まえつつ、広く通用するロジックを提供する必要があり、技術的には大きなチャレンジとなります。また、先に紹介したタグの偶然の一致のようなものでも、よくありがちなタグが一致するより、珍しいタグが一致したときのほうがユーザーにとってのインパクトが大きいと考えられ、主要なタグのみを扱うのでは物足りなさが残ります。
データがない!
機械学習はデータ(学習データ)を大量に食わせることで、それっぽい答えを返せるようにする技術です。そのため、学習に十分な量と質のデータが必要となるのですが、まだ機能がローンチされていないのでこの機能をユーザーが使った行動ログデータがありません。このような状況は機械学習技術を使った機能を新たに作ろうとする場合にしばしば生じます。また、我々は去年設立されたばかりのスタートアップなので開発される機能の多くが新機能であり、このような状況自体がデフォルトであったりもします。そんななか今回 Tag Suggestion 機能を作るにあたって行ったチャレンジを公開してみたいと思います。
最初の実装 -- Entity Extractor

不確実な点が多い機能を開発する際には、最低限の性能を発揮するベースラインを早めに作って、そこから段階的に成長させていくことが重要と考えています。そこで、まずは下記のような構成のロジックにすることにしました。
- ユーザーのプロフィールからテキストデータを抽出
- テキストデータから Entity を抽出
- ユーザーがまだタグとして登録していない Entity を suggest
これはテキスト中の Entity(後述)の抽出をベースにした機能であるので、Entity 抽出機能を Entity Extractor と読んでいます。Entity Extractor はある種のパターンマッチャーなのですが Beatrust における基本的なツールとなります。下記で、抽出される Entity について説明します。
Entity
Beatrust のサービスにおいて重要と思われるキーワード・キーフレーズを Entity とよび、手動で収集・メンテナンスしています。とくに、先に説明したように下記の観点が重要になります。
- 様々な業界固有の語がカバーされていること、
- スキルや資格のような情報だけではなく、趣味やライフスタイルなどに関するものまで幅広く収集されていること
- ノイズが少なく高品質であること
- 必要に応じてカテゴリ情報などを付与してあること
これらの Entity のうちの多くは Web 資源を自前でクローリングしたり、Beatrust のサービスに蓄積されたデータから追加されたりしたものです。下記は Entity の一例です。
Googleスプレッドシート ベンチャー投資 トイプードル Beatrust 東京大学 ウイスキー 感情分析 仲介役 創薬 田舎暮らし ︙
これらの Entity を集積し構造化したものを Entity Dictionary とよんでおり、将来的に Beatrust サービスの根幹となるナレッジベースへと育てていきたいと考えています。ここには記載していませんが、各 Entity にはいくつかの属性情報などを半手動・半自動で付与できるように設計しています。また、話し始めると長くなるので割愛しますが、多言語対応できるようなしくみも作り込んでいます。Entity Dictionary は Beatrust のサービスにおいて非常に重要であると考えており、それをどう設計して構築・メンテナンスしていくかに関しては語りたいことが多々あるのですが、長くなるのでまたの機会にします。
Entity Extractor ベースの Suggestion の結果
サンプルとして私のプロフィール中の corework(自己紹介を自由に記載できる欄)のテキストを使ってみます。
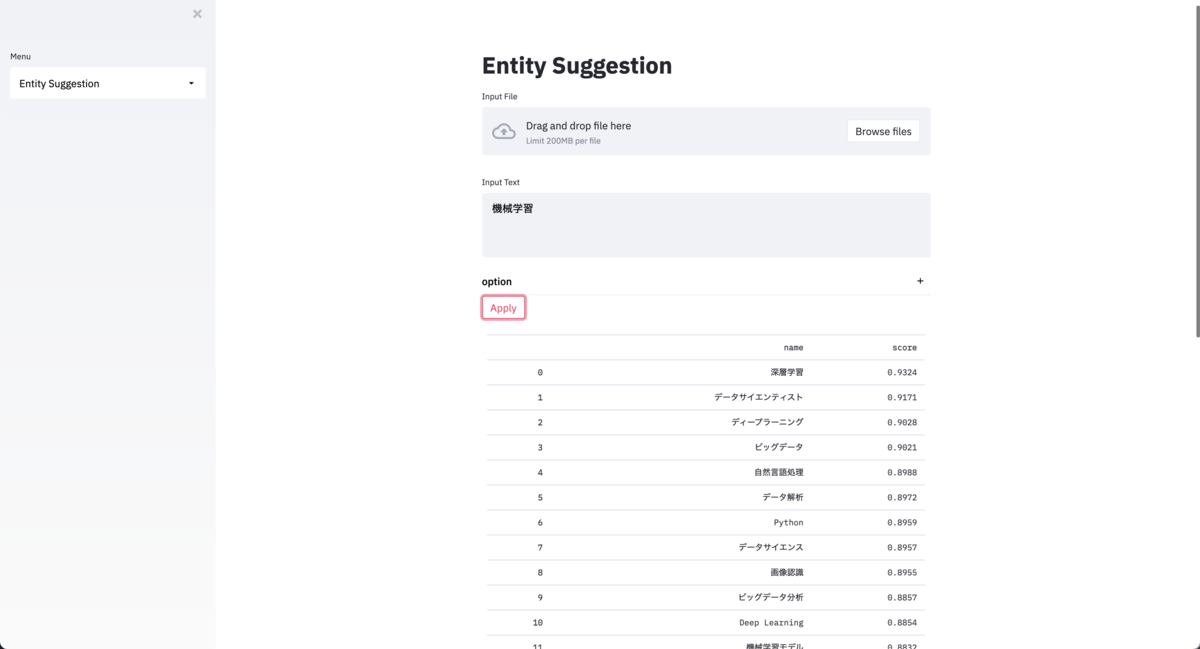
機械学習/データサイエンスまわりを全部やります。 データの持ち方・集め方からどんな機能を実装していくかまで、サービスが運用されていくなかで自然にデータが蓄積され機能を改善していけるための仕組みを考え構築します。 未来を創るために研究も積極的にやっていきたいです。 人間と組織の dynamics を理解して、データ駆動の社会科学をするのが裏ゴール。 ストレングスファインダー 1. 着想 2. 学習欲 3. 戦略性 4. 内省 5. 最上志向 昔書いた記事など - より良い機械学習のためのアノテーションの機械学習 https://tech-blog.abeja.asia/entry/ml-annotation - 機は熟した!グラフ構造に対するDeep Learning、Graph Convolutionのご紹介 https://tech-blog.abeja.asia/entry/2017/04/27/105613 - 異空間への埋め込み!Poincare Embeddingsが拓く表現学習の新展開 https://tech-blog.abeja.asia/entry/poincare-embeddings - 双曲空間でのMachine Learningの最近の進展 https://tech-blog.abeja.asia/entry/hyperbolic_ml_2019 - データに内在する構造をみるための埋め込み手法 https://www.slideshare.net/daynap1204/ss-170631278 - Retail Face Analysis Inside-Out https://www.slideshare.net/daynap1204/retail-face-analysis-insideout - Seeing Unseens with Machine Learning -- 見えていないものを見出す機械学習 https://www.slideshare.net/daynap1204/seeing-unseens-with-machine-learning - 実運用にたえる配送計画エンジンの構築に向けて https://www.nttdata.com/jp/ja/data-insight/2015/091001/ その他リンクなど Github: https://github.com/TatsuyaShirakawa
結果はこちら。抽出された Entity とその出現回数を出力しています。
機械学習 4 Machine Learning 2 データサイエンス 1 研究 1 積極的 1 データ駆動 1 社会科学 1 ストレングスファインダー 1 着想 1 学習欲 1 戦略性 1 内省 1 最上志向 1 アノテーション 1 Deep Learning 1 Graph Convolution 1 表現学習 1 双曲空間 1 Retail 1 Analysis 1 配送計画 1 GitHub 1
抽出しているだけなので当然ですが、それなりに上手く抽出されているように思えます。 ロジックが明示的な機能なので正しく機能しているかどうかも確認しやすく、結果を見ながら辞書拡充するということも非常にやりやすいです。
Entity Extractor ベースの Suggestion の課題点
Entity Extractor ベースを実装する前から認識はしていましたが、Entity Extractor の致命的な欠点は下記の2点です。
- 入力テキストに含まれる Entity しか suggest されない
- ユーザーが suggestion 結果を受容しても Entity Extractor にとっては情報が増えないのでユーザーのアクションに応じた挙動変化ができない
とくに1は致命的で、例えばプロフィール情報のみから suggest しようとすると、suggest された Entity はすでにプロフィールに含まれるものに限定されるので、本質的にプロフィールの情報が増えないということになります。 実際はプロフィールの Tags 以外の箇所にかかれている Entity 相当のキーワードを Tag の方にも登録していないケースはかなり多いので、その意味では効果はあるのですが…
次の実装 -- word2vec ベース
Entity Extraction の欠点を改善するため、word2vec ベースの下記の仕組みを作りました。
プロフィールの embedding
- ユーザーのプロフィールからテキストデータを抽出
- テキストデータから Entity や名詞などの word2vec の語彙に含まれる語句を抽出
- 抽出された語句の embeddings をもとめる
- 3の結果を平均化し、ユーザーの embedding とする
Entity Dictionary に対する類似検索
- ユーザーの embedding と Entity の embedding の類似度(cosine 類似度)が求め、それが高い順に Entity を出力(ただし、すでにタグ化されているものを除く)
前回の実装から工夫したのは、(1) 出力を Entity Dictionary 内の Entity に限定した点、(2) word2vec による embeddings を用いた類似検索にした点です。 それぞれに関して下記で補足します。
出力するタグは Entity Dictionary から選択する
機械学習は放っておくととんでもない出力をすることもあります。そのため最低限のルールは守れるようにするための工夫が欲しくなります。今回は Tag Suggestion の出力を Entity Dictionary に含まれる Entity に限定をすることで対応しました。これを行わないと結構危険で、たとえば後述の word2vec で学習されたモデルでの類似検索時に「女子大生」というような語をクエリーにすると、サービスにふさわしくない語が大量に出力されるようなこともしばしば観察されました…
word2vec ベースの類似検索
word2vec の学習には下記のコーパスを使用しています。
広範なドメインのデータに対応できるように wikipedia を使い、特定ドメインの語に対応できるように独自でクローリングしたデータを追加しています。 これで学習された word2vec で語句の embeddings を求め、それをベースとした類似検索をすることで、入力テキストに含まれない語句の suggest も可能にしています。
レコメンドにおいては word2vec の学習時の negative sampling に用いる語句の unigram 分布を -0.5 乗(!)などにしレアな単語ほど学習字に積極的に選ばれるようにするようなことで精度改善がするというような報告([Benjamin 2020] など)もあり興味があって試してみたのですが、それほど精度変化はなかったです。
word2vec ベースの Suggestion の結果
同じく私のプロフィールを使った結果です。suggest された Entity とそのスコア(cosine 類似度)を表示しています。Entity Extraction で抽出されたものに関してはスコア 1.0 をつけて出力しています。
機械学習 1.0 Machine Learning 1.0 データサイエンス 1.0 研究 1.0 積極的 1.0 データ駆動 1.0 社会科学 1.0 ストレングスファインダー 1.0 着想 1.0 学習欲 1.0 戦略性 1.0 内省 1.0 最上志向 1.0 アノテーション 1.0 Deep Learning 1.0 Graph Convolution 1.0 表現学習 1.0 双曲空間 1.0 Retail 1.0 Analysis 1.0 配送計画 1.0 GitHub 1.0 最適化 0.82 可視化 0.798 データ処理 0.797 データ解析 0.772 ビッグデータ 0.77 自動化 0.766 本質的 0.765 効率化 0.765 問題解決 0.764 アルゴリズム 0.763 課題解決 0.76 画像認識 0.76 構造化 0.758 論理的 0.758 深層学習 0.756 自然言語処理 0.756 主体的 0.755 データ分析 0.754 アプリケーション 0.753 システムアーキテクチャ 0.752 分析ツール 0.75 データマイニング 0.749 ビッグデータ分析 0.749 プログラミングスキル 0.747 大規模データ 0.746 画像処理 0.746 フィードバック 0.742 バックエンド 0.741
関連語を無数に suggest できるようになりました!
word2vec ベースの Suggestion の課題
実施している中でいくつか不満な点が見つかりました。
1. 同系列の単語が suggest されすぎる
たとえば、筆者は京都大学出身なのですが、京都大学に対して suggest される Entity を求めてみると下記のようになります。
京都大学 1.0 大阪大学 0.907 東京大学 0.876 大阪市立大学 0.873 名古屋大学 0.858 九州大学 0.833 神戸大学 0.83 岡山大学 0.816 東北大学 0.816 広島大学 0.805 北海道大学 0.8 大阪府立大学 0.793 山口大学 0.792 大学院 0.787 京都府立大学 0.786 愛媛大学 0.785 奈良大学 0.784 東京工業大学 0.78
たしかに言語的には関連性の強い語が並んでいるものの、これほど複数の大学に関係している方は一般的にはまれですので、京都大学であればもっと他に suggest すべき語もあるはずです。同様のことは過去在籍した会社名などにも言えます。たとえば製薬業界出身者に製薬系の企業を 10 社 suggest するのも多くの場合で不適切と思われます。
2. 入力文中の特定のトピックが優先されがち
たとえば医療 x AIというクエリーに対する suggestion 結果は下記のとおりで、AI に寄った Entity の方が優先されしまっている傾向が見てとれます。この場合は医療に関係する語も出力すべきと思います。
医療 1.0 AI 1.0 機械学習 0.828 ビッグデータ 0.813 画像認識 0.81 課題解決 0.807 人工知能 0.804 ビジネスモデル 0.799 クラウド 0.797 デジタルトランスフォーメーション 0.797 ビックデータ 0.797 データ分析 0.796 テクノロジー 0.793 コンサルテーション 0.793 最先端技術 0.79 データサイエンティスト 0.788 導入支援 0.785 データ解析 0.784 新規サービス 0.783 深層学習 0.782
3. 入力文が長くなってくると、suggestion に尖りがなくなる
おそらく入力文中の語句の embeddings の平均を取っているせいだと思いますが、固有性がうすれ当たり障りのない Entity が suggest される傾向が確認されました。下記はちょっと恣意的ですが、医療、AI、食、不動産というクエリーに対する結果です。
医療 1.0 AI 1.0 食 1.0 不動産 1.0 ビジネスモデル 0.866 コンサルティング 0.824 新規事業 0.821 社長直下 0.817 ベンチャー 0.812 ヘルスケア 0.811 課題解決 0.811 マネジメント 0.809 不動産業 0.806 仕組み作り 0.803 介護施設 0.799 価値創造 0.797 事業戦略 0.796 社会貢献 0.795 立ち上げ 0.794 経営コンサルティング 0.792
再修正 -- MMR ベース
上記を修正するために、下記の対応をしました。
- Entity Dictionary 中の特定のカテゴリ(会社名、学校名など)の Entity に関しては、出力個数を制限する
- 入力文中の word embeddings それぞれに対して suggestion 結果を作って、結果をマージする
1 は Entity Dictionary 中の Entity に属性情報も付与していたため実現可能でした。2 に関しては多少アドホックですが、下記のようにしました。
MMR ベースの Suggestion ロジック
修正版では上記の 3 点を考慮した suggestion をなるべくシンプルに実現することを目指し、下記の 3 つの指標のトレードオフをとることにしました。
- 入力文中の語句の関連 Entity が優先して出力される(relevance)
- 入力文中の重要語句をなるべく優先的に考慮する(importance)
- 入力文中のトピックがなるべくカバーされる(diversity)
なるべく制約の少ないシンプルな実装にしたかったため、下記のようにしています。
1. Relevance の計算
これは今まで通り word embeddings 間の cosine similarity で計算しています。
2. Importance の計算
[Sho2020] でも言及されていますが、word embeddings のノルムの大きさは経験的には語の固有性に関係します(poincare embeddings などの双曲空間への embeddingsで は木の根からの距離がノルムの大きさに対応するので明確ですが、Euclidean な embeddings である word2vec でも近似的にそういう性質が成り立っているのだと思います)。下記は Machine Learning という語と cosine similarity が 0.7 以上となる語群を cosine 類似度、ノルムとともに並べたものです(上位、中位、下位 10 件ずつ)。
アーキテクチャ選定 0.722 6.56 ビジネス課題解決 0.734 6.524 サーバーレスアーキテクチャ 0.702 6.52 統計検定 0.767 6.481 データ戦略 0.765 6.434 keras 0.782 6.379 ビックデータ解析 0.729 6.378 テクノロジーコンサルタント 0.706 6.372 オーディエンスデータ 0.708 6.368 統計モデリング 0.804 6.361 ... 運用保守 0.74 4.918 オンプレミス 0.752 4.906 業務アプリケーション 0.702 4.904 テキストマイニング 0.83 4.902 導入サポート 0.701 4.9 クラウド環境 0.833 4.898 情報理論 0.709 4.894 技術リーダー 0.756 4.893 画像処理技術 0.807 4.892 課題発見 0.775 4.892 ... 問題解決 0.728 3.564 人工知能 0.82 3.56 イノベーション 0.732 3.56 デバイス 0.711 3.556 計測 0.707 3.524 テクノロジー 0.753 3.498 プラットフォーム 0.701 3.425 ソフトウェア 0.738 3.406 コミュニケーション 0.719 3.392 トレンド 0.708 3.31
見ていただけると分かる通り、ノルムが大きい語ほど固有(それが語られる状況が限定的)になっていることが観察されます。この観察に基づき、 を求め、あとで使いやすいように平均値を 1 になるように正規化したものを Importance としました(0.5 は気分で選んだ数値です)。概念的には固有性と重要性は異なるのですが、尖った語句を重要視したいという文脈を仮定するならば一旦はこれでやっておいて後で必要に応じて改善しようと考えています。
3. Diversity の計算
Diversity を考慮した reranking 手法としては MMR(Maximal Marginal Relevance, [Jaime1998])が有名です。MMR では、クエリー に対してすでに
個(
)の suggestion が選ばれているときに
個目の suggestion
を、
が最大になるような として選びます。今回もシンプルさをとって MMR を採用しました。
similarity としては、word vector 間の cosine similarity を使いました。
4. 修正版 Suggestion アルゴリズム
上記をあわせて下記のようなアルゴリズムを構成しました。
- ユーザーのプロフィールからテキストデータを抽出
- テキストデータから Entity や名詞などの word2vec の語彙に含まれる語句を抽出
- 抽出された語句の embeddings をもとめる
- 3 の embeddings のノルムから入力文の語句の Importance を求める
- 3 の embeddings ごとに類似検索をかけ、類似度(Relevance)Top-N のリストをつくる
- 5 のリストの類似度に 4 の Importance を乗じる(これで得た値を weighted relevance とよぶことにします)
- 特定カテゴリの Entity の出力を抑制しつつ、weighted relevance を similarity として MMR により最終リストを構成
修正版 Suggestion ロジックの結果
下記では MMR の効果がわかりやすいよう、 としてみます。数値は Importance * Relevance です。
さきほどより多様性の大きい結果になっていることがわかると思います(その分精度は落ちてしまいますが…)。
京都大学:
京都大学 1.0 共同研究 0.71 講座 0.628 博士 0.674 大学院 0.787 史学 0.712 研究室 0.737 研究所 0.666 哲学 0.602 科学 0.676
大学名がやたら並ぶということはなくなりました。
医療 x AI:
医療 0.984 データアナリティクス 0.778 人工知能 0.866 スマートシティ 0.731 システムエンジニア 0.82 チャットボット 0.826 ビッグデータ 0.893 ドローン 0.792 技術ベンチャー 0.721 自動化ソリューション 0.79
だとこのケースでは尖り具合がなくなって微妙かもしれません。実際はもう少し
を大きくとって diversity の影響をへらすべきでしょう。
医療、AI、食、不動産:
不動産 1.032 食 0.945 医療 0.973 強化学習 0.7 デジタル技術 0.813 エンジニア 0.809 ロボット技術 0.702 音声認識 0.818 機械学習技術 0.817 ドローン 0.783
これは先程より悪くないかもしれません。
私のプロフィール:
アノテーション 1.2 戦略性 1.133 内省 1.104 サイエンス 1.043 slack 1.106 微分方程式 0.995 データサイエンス 1.185 クルマ 0.741 研究 0.957 宅配 0.838
こちらも では精度がいまいちなので、実際には
はもう少し大きくとっておくべきです。
このように MMR のパラメータ 次第では精度を損ねますが、多様性と精度のトレードオフを取れるようになります。あとは後述の評価データでチューニングをしたり、word2vec の精度をさらに上げたり…などをしていくことになります。後者に関しては Common Crawl から作ったデータ(日本語のデータで重複除去後ですが、学習コーパスとしては日本語 wikipedia の 13 倍くらいのサイズになりました)で頑張って学習してみたりなどもしたのですが、そちらの詳細はまたの機会にゆずって、参考までに私の関連 tweet だけ貼っておきます(Common Crawlから言語ごとにデータを分類し、重複除去をした OSCAR という公開コーパスを利用して検証したときのものです)。
OSCARの日本語コーパス(重複除去版)が217,755,988行、41,160,724,041文字だった。https://t.co/2rRsyrWWmA
— Tastuya Shirakawa (@s_tat1204) 2020年9月27日
最近出たWiki-40Bは多言語だけど400億文字くらいらしい。https://t.co/YMBLRM67Zl
Common Crawlはやっぱり化け物みたいに大きいな。
その他の開発する上での工夫
作った機能は、早めに Dog Fooding し評価することが重要です。そのため、下記のようなことを行いました。
1. Slack Bot
Beatrust ではコミュニケーションツールとして Slack を使っていますが、Slack の魅力のひとつは Bot がかなり容易に作れることです。具体的にはテキストやファイルなどを入力するとそこから必要に応じてテキスト抽出し(自己満足のために遊んでもらえるように無駄に OCR もしてみました)TagをSuggest する Bot を作成して、社内で遊んでもらうようにしました。これは非常に好評で、みんな思い思いに面白い入力を入れてくるので、思わぬ改善ポイントが発覚したりして非常に有用でした。実験からフィードバックまで Slack 上で完結するので、面白い結果が出たときにメンションしたり転載するだけで共有できる手軽さも最高です。
下記は弊社のメンバー紹介ページのキャプチャ画像を Bot に投げ入れたものです。

2. Demo
Slack Bot では細かい機能のチューニングや結果の柔軟な可視化などが難しいです。そこで、Streamlit を使って、それっぽいデモを作って試しました。簡単にそれっぽいデモが作れるので気分があがっておすすめです。これにより技術的な試行錯誤がやりやすくなりました。正直自分自身が一番のユーザーだった気がしますが、いろんな状況でのテストをいつでも簡単にできるのでとても捗りました。なお、デモをチープに共有するために Cloud Run に Streamlit app をデプロイしましたが、もっと良い方法があれば知りたいです。ご存じの方がいたら教えてください。あと、Cloud Run だと私が知っている限り、いい感じのアクセスコントロールを実現するのがめんどくさいのでそちらも簡単な方法があれば。。。
3. Working Out Loud
発信しないために気づけてもらえないことによる機会損失は思ったより大きいです。そのため、Slack 上でできるだけやっていること、できたものをどんどん発信するようにしています(発信というより垂れ流しに近いです)。Working Out Loud というそうなのですが、自分から発信することで、色んな人から気づきをもらえたりしますし、案外あとから振り返りたいときにも便利だったりします(Slack の検索機能がもう少し改善されれば…)。 quipper.hatenablog.com
4. Suggest 結果に対する Annotation
ユーザーの行動ログデータがない状況なので、独自でアノテーションを実施し、suggestion 結果に対して人による評価を行っています。具体的には、tag suggestion の結果に対して、(1) 適切、(2) 不適切、(3) 分からないの3 種類のうちのいずれかに振り分けてもらうアノテーションを実施しました。これにより得られたデータを評価データにしてモデルの評価を行ったり、チューニングを行ったりすることができます。アノテーションの UI をどうしようかと思って slack 上でつぶやいたら、そんな私のつぶやきを社内のスプレッドシートの扱いが抜群に得意なメンバーが拾い上げて、素敵な UI をパパっと作ってくれました。つぶやいてから 1 時間後には下記のすばらしい作品が仕上がっていました。すごい。


最後に
語りたいことが多くてすこし長くなってしまいましたが、機能実装にあたってのトライが伝われば幸いです。
Beatrust では組織に属する人々がよりよくコラボレーションができるようにするためのあらゆるしかけを作っていきます。人や組織のような硬直したロジックが通用しにくい状況では機械学習のようなデータ駆動の技術が重要だと思っています。また、日本語話者だけではなく英語話者もこれからユーザーとして増えてくるとすると Cross/Multi Lingual 対応が必要であったり、個社ごとに固有の社内用語に対応しようと思うとそれを実現しやすいアーキテクチャを構築したりと課題も山盛りです。個人的にはやりすぎなくらい技術で殴り倒したいです。
とはいえ、まだ創業したてなこともあり、実現したいものにたいして人手が圧倒的に足りないのが現状です。。。 もし本記事や Beatrust 自体に興味を持っていただけたら、下記からお声がけいただけたら幸いです。 カジュアル面談のご希望もお気軽にどうぞ。Twitter 上で私に直接お声がけいただくのも welcome です!
Beatrust の採用情報ページ
Data Scientist の採用情報ページ(データ分析、機械学習など)
私の Twitter アカウント
参考文献
[Benjamin2019] Benjamin P. Chamberlain+, "Tuning Word2vec for Large Scale Recommendation Systems", RecSys2020
[Sho2020] Sho Yokoi+, "Word Rotator’s Distance", EMNLP 2020
[Jaime1998] Jaime Carbonell+, "The use of MMR, diversity-based reranking for reordering documents and producing summaries", SIGIR 1998